Linux 系统是如何收发网络包的?
# Linux 系统是如何收发网络包的?
# 网络模型
复习一下谈的最多的 OSI 网络模型,该模型主要有 7 层,每一层负责的职能都不同,如下:
- 应用层,负责给应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容另一个系统能识别的格式。
- 会话层,负责建立、管理和终止表示层实体之间的通信会话。
- 传输层,负责端到端的数据传输。
- 网络层,负责数据的路由、转发、分片。
- 数据链路层,负责数据的封帧和差错检测,以及 MAC 寻址。
- 物理层,负责在物理网络中传输数据帧.
但由于 OSI 模型实在太复杂,提出的也只是概念理论上的分层,并没有提供具体的实现方案。
事实上,我们比较常见,也比较实用的是四层模型,即 TCP/IP 网络模型,Linux 系统正是按照这套网络模型来实现网络协议栈的。
TCP/IP 网络模型共有 4 层,分别是应用层、传输层、网络层和网络接口层,每一层负责的职能如下:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、DNS、FTP 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、分片、路由、转发,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如网络包的封帧、 MAC 寻址、差错检测,以及通过网卡传输网络帧等。
TCP/IP 网络模型相比 OSI 网络模型简化了不少,也更加易记,它们之间的关系如下图:
(OSI 模型和 TCP/IP 模型对应关系)
不过,我们常说的七层和四层负载均衡,是用 OSI 网络模型来描述的,七层对应的是应用层,四层对应的是传输层。
# Linux 网络协议栈
网络数据传输的过程就像出门前穿衣服的过程:
- 如果把自己的身体比作应用层中的数据,传输层中的 TCP 头就是打底衣服,网络层中 IP 头就是外套,网络接口层的帧头和帧尾分别是帽子和鞋子。
- 冬天要出门时,会先穿个打底衣服,再套上保暖外套,最后穿上帽子和鞋子。
这个过程就好像我们把 TCP 协议通信的网络包发出去的时候,会把应用层的数据按照网络协议栈层层封装和处理,如下图所示:
(应用层数据在每一层的封装格式)
其中:
- 传输层,给应用数据前面增加了 TCP 头。
- 网络层,给 TCP 数据包前面增加了 IP 头。
- 网络接口层,给 IP 数据包前后分别增加了帧头和帧尾。
这些新增的头部和尾部,都有各自的作用,也都是按照特定的协议格式填充。既然每一层都增加了各自的协议头,那自然网络包的大小就增大了,但物理链路并不能传输任意大小的数据包,所以在以太网中,规定了最大传输单元(MTU)是 1500 字节,也就是规定了单次传输的最大 IP 包大小。
当网络包超过 MTU 的大小,就会在网络层分片,以确保分片后的 IP 包不会超过 MTU 大小。如果 MTU 越小,需要的分包就越多,那么网络吞吐能力就越差,相反的,如果 MTU 越大,需要的分包就越少,那么网络吞吐能力就越好。
知道了 TCP/IP 网络模型,以及网络包的封装原理后,那么 Linux 网络协议栈的样子就可以画出来了,它其实就类似于 TCP/IP 的四层结构:
(Linux 网络协议栈)
从上图的的网络协议栈,你可以看到:
- 应用程序需要通过系统调用,来跟 Socket 层进行数据交互。
- Socket 层的下面就是传输层、网络层和网络接口层。
- 最下面的一层,则是网卡驱动程序和硬件网卡设备。
小贴士
LVS(Linux Virtual Server),是一个虚拟的服务器集群系统,主要是为了解决高并发,大数据量的问题,后由 Linux 内核收录成为 Linux 内核的一部分。
Socket 是应用层与 TCP/IP 协议簇通信的中间软件抽象层,它是一组接口。Socket 的大致流程是:服务器端先初始化 Socket,然后与端口绑定(bind),对端口进行监听(listen),调用 accept 阻塞,等待客户端连接。在这时如果有个客户端初始化一个 Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
ICMP 是因特网控制报文协议,通常被认为是 IP 层的一个组成部分。它是在 IP 数据报内被传输的,且通常来说都是内核帮你实现的,系统自身就支持了,并不需要开个服务监听对应端口、建立连接。ICMP 报文通常被 IP 层或更高协议(TCP/UDP)使用。
ARP(Address Resolution Protocol)是地址解析协议,用于完成从 IP 地址到 MAC 地址的映射(因此基于 ARP 协议只需要拿到 IP 地址就能确定一台计算机)。因为 IP 协议使用了 ARP,所以通常将 ARP 归为网络层,但 ARP 协议用于把网络层使用的 IP 地址映射到数据链路层使用的硬件地址,所以也可以把 ARP 归为数据链路层。
前置知识铺垫完毕,开始进入正题。
# Linux 接收网络包的流程
网卡是计算机里的一个硬件,专门负责接收和发送网络包,当网卡接收到一个网络包后,会通过 DMA 技术,将网络包写入到指定的内存地址,也就是写入到 Ring Buffer ,这个是一个环形缓冲区,接着就会告诉操作系统这个网络包已经到达。
# 告诉操作系统网络包已到达
那应该怎么告诉操作系统这个网络包已经到达了呢?
最简单的一种方式就是触发中断,也就是每当网卡收到一个网络包,就触发一个中断告诉操作系统。
但是,这存在一个问题,在高性能网络场景下,网络包的数量会非常多,那么就会触发非常多的中断,要知道当 CPU 收到了中断,就会停下手里的事情,而去处理这些网络包,处理完毕后,才会回去继续其他事情,那么频繁地触发中断,则会导致 CPU 一直没完没了的处理中断,而导致其他任务可能无法继续前进,从而影响系统的整体效率。
所以为了解决频繁中断带来的性能开销,Linux 内核在 2.6 版本中引入了 NAPI 机制,它是混合「中断和轮询」的方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后 poll 的方法来轮询数据。
因此,当有网络包到达时,会通过 DMA 技术,将网络包写入到指定的内存地址,接着网卡向 CPU 发起硬件中断,当 CPU 收到硬件中断请求后,根据中断表,调用已经注册的中断处理函数。
硬件中断处理函数会做如下的事情:
- 需要先「暂时屏蔽中断」,表示已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提高效率,避免 CPU 不停的被中断。
- 接着,发起「软中断」,然后恢复刚才屏蔽的中断。
至此,硬件中断处理函数的工作就已经完成。
硬件中断处理函数做的事情很少,主要耗时的工作都交给软中断处理函数了。
# 软中断的处理
内核中的 ksoftirqd 线程专门负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据。
ksoftirqd 线程会从 Ring Buffer 中获取一个数据帧,用 sk_buff 表示,从而可以作为一个网络包交给网络协议栈进行逐层处理。
# 网络协议栈
首先,会先进入到网络接口层,在这一层会检查报文的合法性,如果不合法则丢弃,合法则会找出该网络包的上层协议的类型,比如是 IPv4,还是 IPv6,接着再去掉帧头和帧尾,然后交给网络层。
到了网络层,则取出 IP 包,判断网络包下一步的走向,比如是交给上层处理还是转发出去。当确认这个网络包要发送给本机后,就会从 IP 头里看看上一层协议的类型是 TCP 还是 UDP,接着去掉 IP 头,然后交给传输层。
传输层取出 TCP 头或 UDP 头,根据四元组「源 IP、源端口、目的 IP、目的端口」 作为标识,找出对应的 Socket,并把数据放到 Socket 的接收缓冲区。
最后,应用层程序调用 Socket 接口,将内核的 Socket 接收缓冲区的数据「拷贝」到应用层的缓冲区,然后唤醒用户进程。
至此,一个网络包的接收过程就已经结束了。下图左边部分描述的就是网络包接收的流程,右边部分刚好反过来,它是网络包发送的流程。
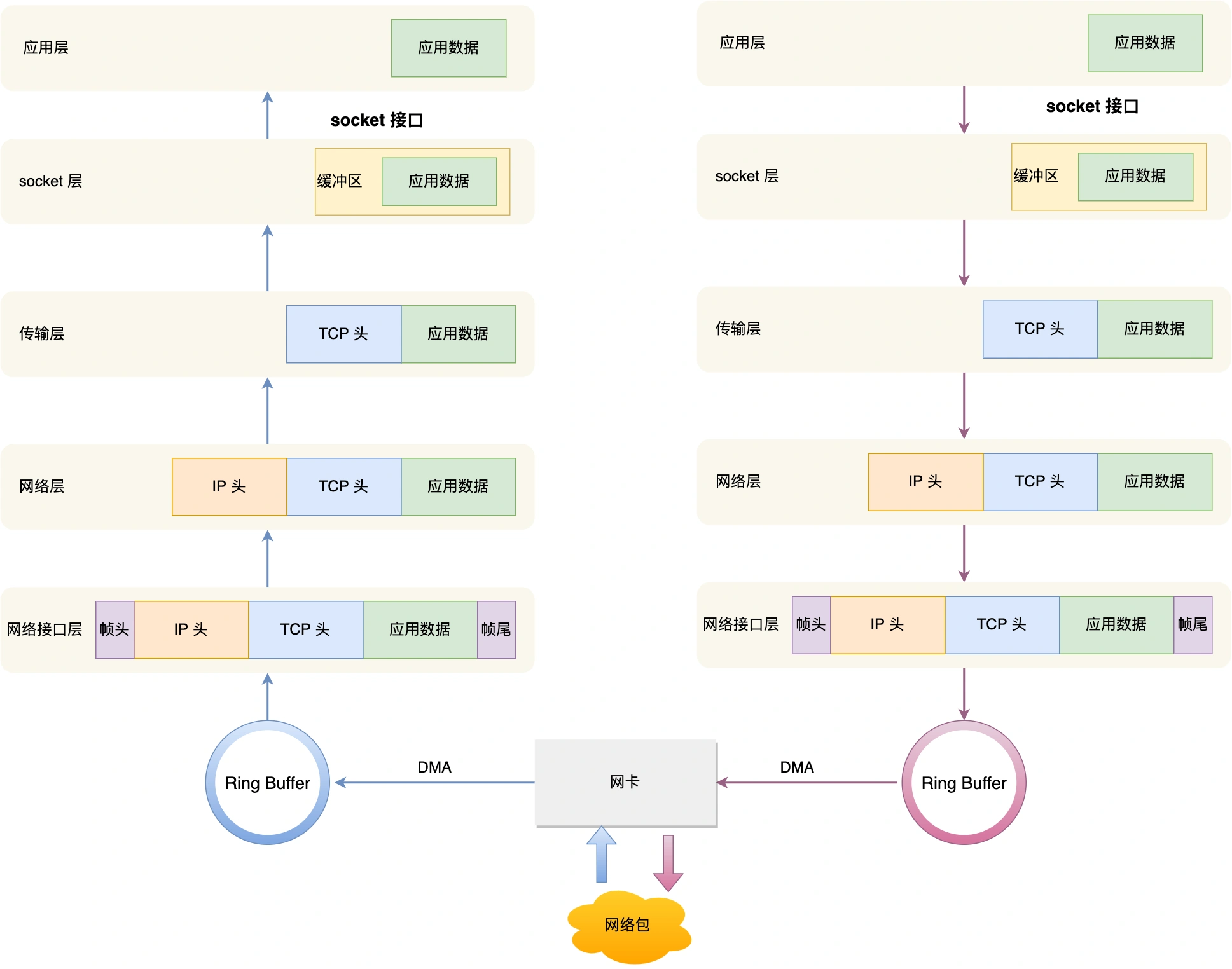
(网络包接收和发送流程)
# Linux 发送网络包的流程
如上图的右半部分,发送网络包的流程正好和接收流程相反。
# 应用层
首先,应用程序会调用 Socket 发送数据包的接口,由于这个是系统调用,所以会从用户态陷入到内核态中的 Socket 层,内核会申请一个内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加入到发送缓冲区。
# 传输层
接下来,网络协议栈从 Socket 发送缓冲区中取出 sk_buff,并按照 TCP/IP 协议栈从上到下逐层处理。
如果使用的是 TCP 传输协议发送数据,那么先拷贝一个新的 sk_buff 副本,这是因为 sk_buff 后续在调用网络层,最后到达网卡发送完成的时候,这个 sk_buff 会被释放掉。而 TCP 协议是支持丢失重传的,在收到对方的 ACK 之前,这个 sk_buff 不能被删除。所以内核的做法就是每次调用网卡发送的时候,实际上传递出去的是 sk_buff 的一个拷贝,等收到 ACK 再真正删除。
接着,对 sk_buff 填充 TCP 头。这里提一下,sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层我们称为 segment(段),在 IP 层我们叫 packet(包),在数据链路层称为 frame(帧)。
你可能会好奇,为什么全部数据包只用一个结构体来描述呢?协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
- 当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb -> data 的值,来逐步剥离协议首部。
- 当要发送报文时,创建
sk_buff结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb -> data 的值来增加协议首部。
至此,传输层的工作也就都完成了。
# 网络层
然后交给网络层,在网络层里会做这些工作:选取路由(确认下一跳的 IP)、填充 IP 头、netfilter 过滤、对超过 MTU 大小的数据包进行分片。处理完这些工作后会交给网络接口层处理。
# 网络接口层
网络接口层会通过 ARP 协议获得下一跳的 MAC 地址,然后对 sk_buff 填充帧头和帧尾,接着将 sk_buff 放到网卡的发送队列中。
# 通知网卡有包要发送
这一些工作准备好后,会触发「软中断」告诉网卡驱动程序,这里有新的网络包需要发送,驱动程序会从发送队列中读取 sk_buff,将这个 sk_buff 挂到 RingBuffer 中,接着将 sk_buff 数据映射到网卡可访问的内存 DMA 区域,最后触发真实的发送。
# 完成网络包的发送
当数据发送完成以后,其实工作并没有结束,因为内存还没有清理。当发送完成的时候,网卡设备会触发一个硬中断来释放内存,主要是释放 sk_buff 内存和清理 RingBuffer 内存。
最后,当收到这个 TCP 报文的 ACK 应答时,传输层就会释放原始的 sk_buff 。
小贴士
发送网络数据的时候,涉及几次内存拷贝操作?
- 第一次,调用发送数据的系统调用的时候,内核会申请一个内核态的
sk_buff内存,将用户待发送的数据拷贝到sk_buff内存,并将其加入到发送缓冲区。 - 第二次,在使用 TCP 传输协议的情况下,从传输层进入网络层的时候,每一个
sk_buff都会被克隆一个新的副本出来。副本sk_buff会被送往网络层,等它发送完的时候就会释放掉,然后原始的sk_buff还保留在传输层,目的是为了实现 TCP 的可靠传输,等收到这个数据包的 ACK 时,才会释放原始的sk_buff。 - 第三次,当 IP 层发现
sk_buff大于 MTU 时才需要进行。会再申请额外的sk_buff,并将原来的sk_buff拷贝为多个小的sk_buff。
# 总结
电脑与电脑之间通常都是通过话网卡、交换机、路由器等网络设备连接到一起,那由于网络设备的异构性,国际标准化组织定义了一个七层的 OSI 网络模型,但是这个模型由于比较复杂,实际应用中并没有采用,而是采用了更为简化的 TCP/IP 模型,Linux 网络协议栈就是按照了该模型来实现的。
TCP/IP 模型主要分为应用层、传输层、网络层、网络接口层四层,每一层负责的职责都不同,这也是 Linux 网络协议栈主要构成部分。
当应用程序通过 Socket 接口发送数据包,数据包会被网络协议栈从上到下进行逐层处理后,才会被送到网卡队列中,随后由网卡将网络包发送出去。
而在接收网络包时,同样也要先经过网络协议栈从下到上的逐层处理,最后才会被送到应用程序。
在网上看到一张不错的动图,附上:
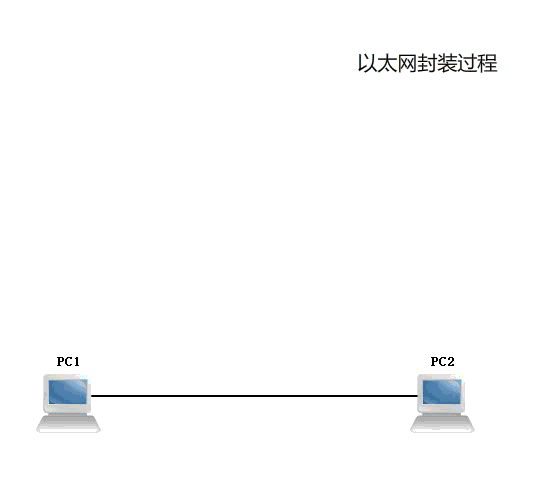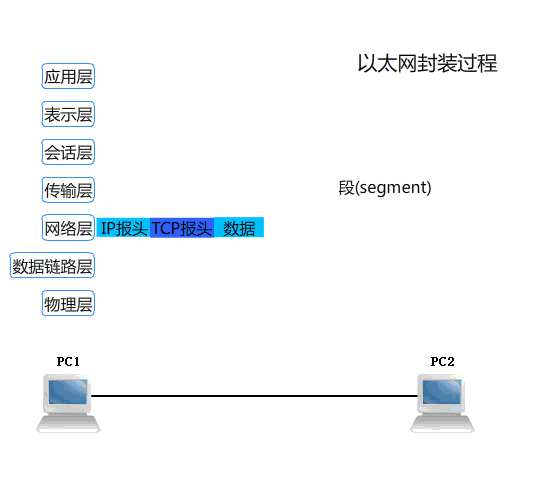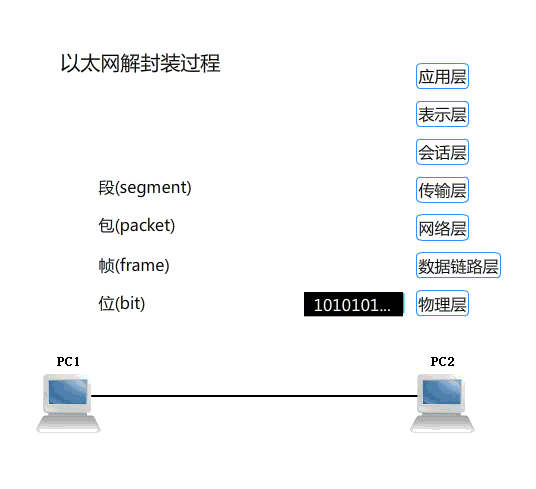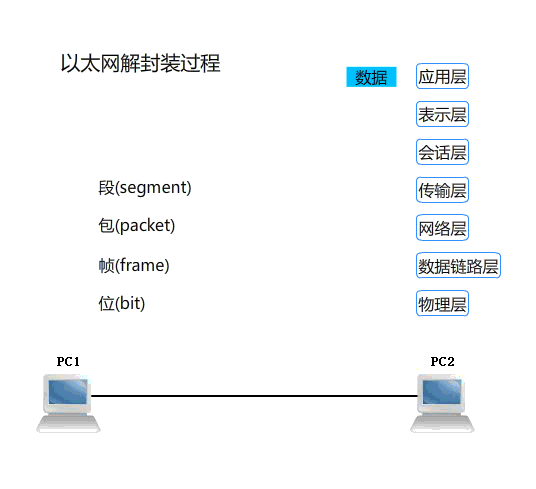
(OSI 七层协议数据传输的封包与解包过程)
(完)