如果已经建立了连接,但是客户端突然出现故障了怎么办?
# 如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP 有一个机制是保活机制。这个机制的原理是这样的:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
1
2
3
2
3
tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制。tcp_keepalive_intvl=75:表示每次检测间隔 75 秒。tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
(TCP 发现一个「死亡」连接所需要的时间)
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
如果开启了 TCP 保活,需要考虑以下几种情况:
- 第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 第二种,对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
- 第三种,是对端程序崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
TCP 保活的这个机制检测的时间是有点长,我们可以自己在应用层实现一个心跳机制。
比如,WEB 服务软件(例如 Nginx)一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,WEB 服务软件就会启动一个定时器,如果客户端在完成一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
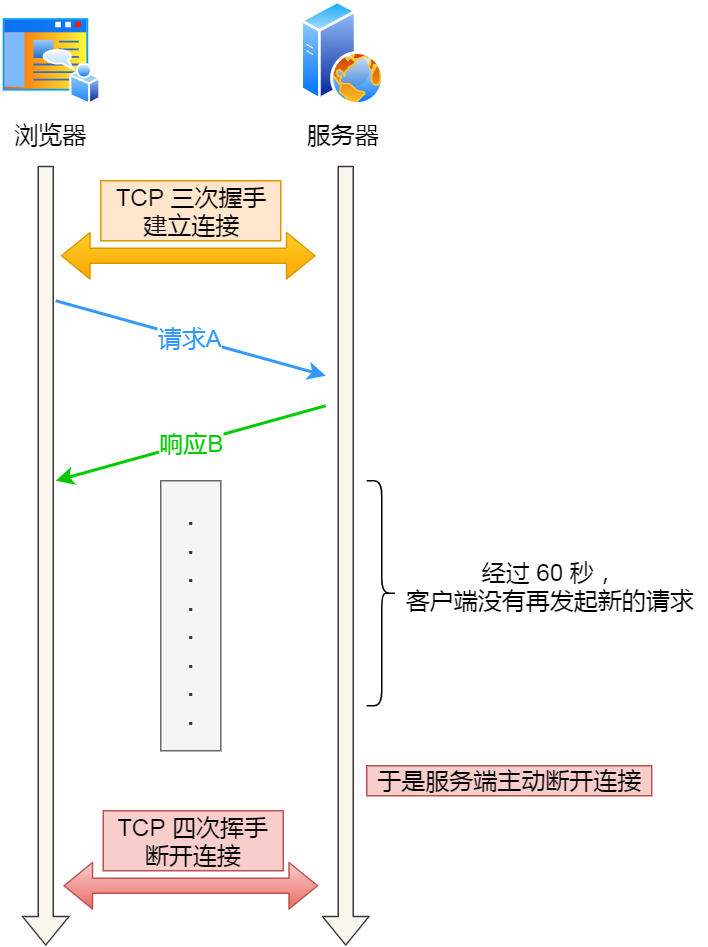
(WEB 服务软件的 HTTP 长连接超时机制)
(完)